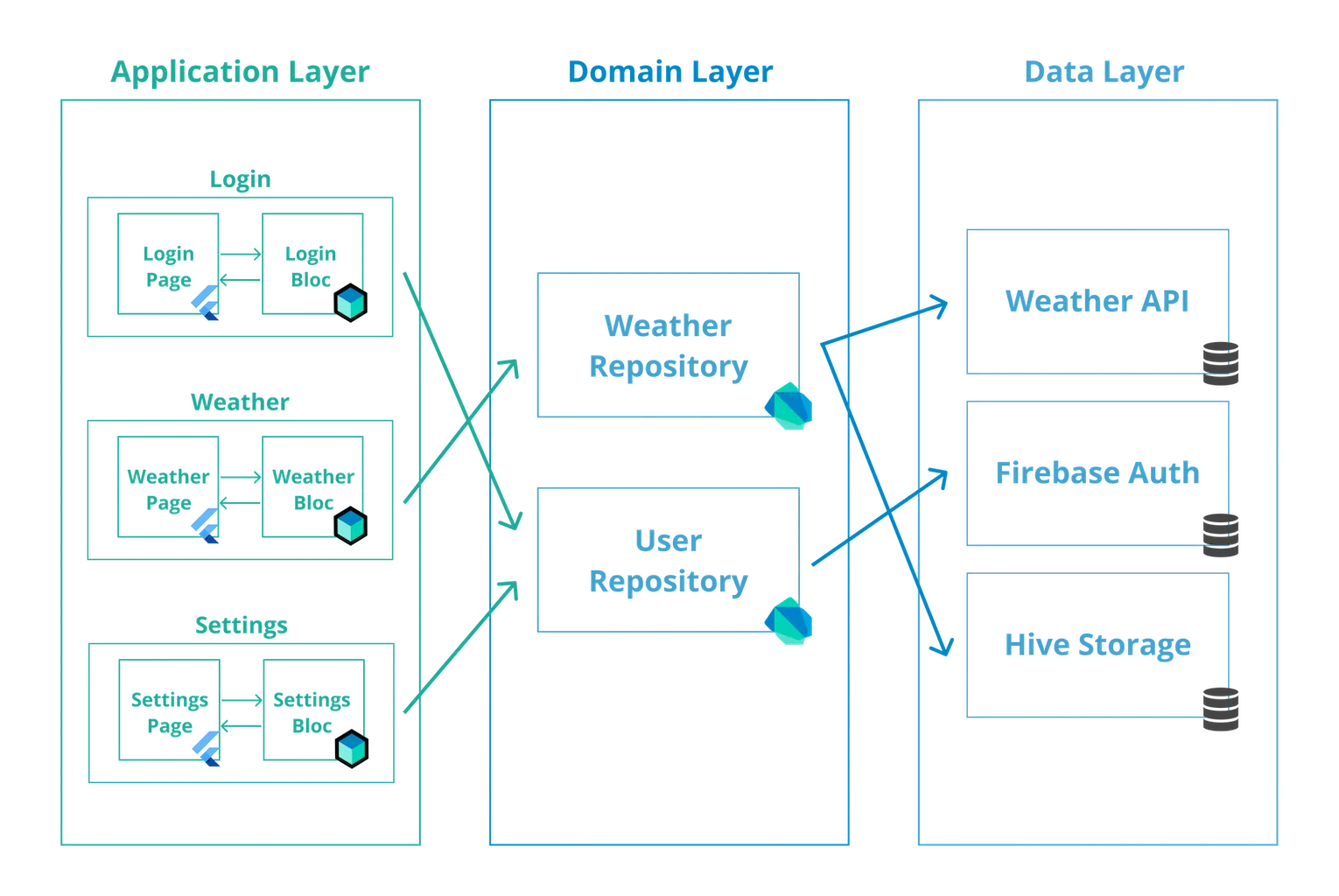
Architecture

L’utilisation de la librairie bloc nous permet de séparer notre application en trois couches :
- Presentation
- Logique Métier (Business Logic)
- Data
- Repository
- Data Provider
Nous allons commencer avec la couche la plus basse (la plus éloignée de l’interfacer utilisateur) et remonter jusqu’à la couche de Présentation.
Couche Data
Section intitulée « Couche Data »Le rôle de la couche Data est de récupérer et de manipuler des données provenant d’une ou plusieurs sources.
La couche Data peut être divisée en deux parties :
- Repository
- Data Provider
Cette couche est le niveau le plus bas de l’application, elle interagit avec les bases de données, les requêtes réseau et d’autres sources de données asynchrones.
Data Provider
Section intitulée « Data Provider »Le rôle du Data Provider est de fournir des données brutes. Il doit être générique et polyvalent.
Le Data Provider permet généralement d’interagir avec des API simple afin
d’effectuer des opérations
CRUD. Nous
pourrions avoir des méthodes createData, readData, updateData, et
deleteData qui feront partie de notre couche Data.
class DataProvider { Future<RawData> readData() async { // Read from DB or make network request etc... }}Repository
Section intitulée « Repository »La couche Repository est un wrapper d’un ou plusieurs Data Provider avec lesquels la couche Bloc communique.
class Repository { final DataProviderA dataProviderA; final DataProviderB dataProviderB;
Future<Data> getAllDataThatMeetsRequirements() async { final RawDataA dataSetA = await dataProviderA.readData(); final RawDataB dataSetB = await dataProviderB.readData();
final Data filteredData = _filterData(dataSetA, dataSetB); return filteredData; }}Comme vous pouvez le constater, notre couche Repository peut interagir avec plusieurs Data Provider et effectuer des transformations sur les données avant de transmettre le résultat à la couche Logic Métier.
Couche Logique Métier (Business Logic layer)
Section intitulée « Couche Logique Métier (Business Logic layer) »La fonction de la couche de Logique Métier est de répondre aux entrées provenant de la couche Présentation avec de nouveaux états. Cette couche peut dépendre d’un ou plusieurs Repository afin de récupérer les données nécessaires à la construction de l’état de l’application.
Considérez la couche Logique Métier comme le pont entre l’interface utilisateur (couche Présentation) et la couche Data. La couche Logique Métier est informée des événements/actions de la couche Présentation et communique alors avec le Repository afin de construire un nouvel état que la couche Présentation pourra appliquer.
class BusinessLogicComponent extends Bloc<MyEvent, MyState> { BusinessLogicComponent(this.repository) { on<AppStarted>((event, emit) { try { final data = await repository.getAllDataThatMeetsRequirements(); emit(Success(data)); } catch (error) { emit(Failure(error)); } }); }
final Repository repository;}Communication de Bloc-à-Bloc
Section intitulée « Communication de Bloc-à-Bloc »Because blocs expose streams, it may be tempting to make a bloc which listens to another bloc. You should not do this. There are better alternatives than resorting to the code below: Comme les blocs mettent à disposition des flux, il peut être tentant de créer un bloc qui écoute un autre bloc. Vous ne devriez pas faire ça. Il existe de meilleures alternatives que le code ci-dessous :
class TightlyCoupledBloc extends Bloc { final OtherBloc otherBloc; late final StreamSubscription otherBlocSubscription;
TightlyCoupledBloc(this.otherBloc) { // No matter how much you are tempted to do this, you should not do this! // Keep reading for better alternatives! otherBlocSubscription = otherBloc.stream.listen((state) { add(MyEvent()); }); }
@override Future<void> close() { otherBlocSubscription.cancel(); return super.close(); }}Bien que le code ci-dessus ne comporte pas d’erreurs, il présente un problème plus important : il crée une dépendance entre deux blocs.
En règle générale, il faut éviter à tout prix les dépendances entre deux entités de la même couche architecturale, car elles créent un couplage fort difficile à maintenir. Étant donné que ces deux blocs résident tous les deux dans la couche architecturale de la Logique Métier, aucun des deux blocs ne devraient connaître l’existence de l’un autre bloc.
Un bloc ne doit recevoir des informations que par le biais d’événements et de Repository injectés (c’est-à-dire des Repository qui sont passés au bloc via son constructeur).
Si vous êtes dans une situation où un bloc doit répondre à un autre bloc, vous avez deux autres options. Vous pouvez soit faire remonter le problème d’une couche (couche de Présentation), soit le faire descendre d’une couche (couche Domain).
Relier des Blocs à travers la couche Présentation
Section intitulée « Relier des Blocs à travers la couche Présentation »Vous pouvez utiliser un BlocListener pour écouter un bloc et ajouter un
événement à un autre bloc lorsque le premier change.
class MyWidget extends StatelessWidget { const MyWidget({Key? key}) : super(key: key);
@override Widget build(BuildContext context) { return BlocListener<FirstBloc, FirstState>( listener: (context, state) { // When the first bloc's state changes, this will be called. // // Now we can add an event to the second bloc without it having // to know about the first bloc. context.read<SecondBloc>().add(SecondEvent()); }, child: TextButton( child: const Text('Hello'), onPressed: () { context.read<FirstBloc>().add(FirstEvent()); }, ), ); }}Le code ci-dessus empêche SecondBloc d’avoir besoin de connaître FirstBloc,
créant ainsi un couplage faible. L’application
flutter_weather
utilise cette technique
pour changer le thème de l’application en fonction des informations
météorologiques reçues.
Dans certains cas, il n’est pas préférable de coupler deux blocs dans la couche Présentation. En revanche, il est souvent logique que deux blocs partagent la même source de données et se mettent à jour lorsque ces données changent.
Relier des Blocs à travers la couche Domain
Section intitulée « Relier des Blocs à travers la couche Domain »Deux blocs peuvent écouter un flux provenant d’un Repository et mettre à jour leur état indépendamment l’un de l’autre chaque fois que les données du Repository changent. L’utilisation de Repository réactifs pour maintenir la synchronisation des états est courante dans les applications d’entreprise à grande échelle.
En premier lieu, créez ou utilisez un Repository qui met à disposition un flux
de données (Stream). Par exemple, le Repository suivant met à disposition un
Stream infini comportant cinq idées d’applications.
class AppIdeasRepository { int _currentAppIdea = 0; final List<String> _ideas = [ "Future prediction app that rewards you if you predict the next day's news", 'Dating app for fish that lets your aquarium occupants find true love', 'Social media app that pays you when your data is sold', 'JavaScript framework gambling app that lets you bet on the next big thing', 'Solitaire app that freezes before you can win', ];
Stream<String> productIdeas() async* { while (true) { yield _ideas[_currentAppIdea++ % _ideas.length]; await Future<void>.delayed(const Duration(minutes: 1)); } }}Le même Repository peut être injecté dans chaque bloc qui doit réagir aux
nouvelles idées d’applications. Voici un AppIdeaRankingBloc qui crée un état
pour chaque idée d’application provenant du Repository ci-dessus :
class AppIdeaRankingBloc extends Bloc<AppIdeaRankingEvent, AppIdeaRankingState> { AppIdeaRankingBloc({required AppIdeasRepository appIdeasRepo}) : _appIdeasRepo = appIdeasRepo, super(AppIdeaInitialRankingState()) { on<AppIdeaStartRankingEvent>((event, emit) async { // When we are told to start ranking app ideas, we will listen to the // stream of app ideas and emit a state for each one. await emit.forEach( _appIdeasRepo.productIdeas(), onData: (String idea) => AppIdeaRankingIdeaState(idea: idea), ); }); }
final AppIdeasRepository _appIdeasRepo;}Pour en savoir plus sur l’utilisation des flux avec Bloc, voir How to use Bloc with streams and concurrency.
Couche Presentation
Section intitulée « Couche Presentation »Le rôle de la couche Presentation est de déterminer comment elle doit s’afficher, en fonction d’un ou plusieurs états de bloc. Elle doit également gérer les entrées de l’utilisateur et les événements du cycle de vie de l’application.
La plupart des flux d’applications commencent par un événement AppStart qui
déclenche la récupération des données qui vont être présentées à l’utilisateur.
Dans ce scénario, la couche Presentation provoquerait un événement AppStart.
En plus de cela, elle devra déterminer ce qu’il faut afficher à l’écran en fonction de l’état de la couche Bloc.
class PresentationComponent { PresentationComponent({required this.bloc}) { bloc.add(AppStarted()); }
final Bloc bloc;
build() { // render UI based on bloc state }}Jusqu’à présent, bien que nous ayons vu quelques extraits de code, tout cela est resté assez théorique. Dans la section tutoriel, nous allons mettre en pratique ces concepts en réalisant plusieurs exemples d’applications.